
The Impact of Bad Data on Modern AI Projects (and How to Fix It)
“Why data quality, not the model, is becoming the biggest success factor in enterprise AI”
AI's Hidden Weak Link
The enterprise AI conversation has been dominated by models. Which LLM should we license? Should we fine-tune or use RAG? What about open-source versus proprietary? These are the wrong questions to start with.
The AI boom is exposing a truth that data teams have known for years: most organizations are building on a foundation of poor-quality data. Decades of neglected data strategy are now coming due. The models are powerful, but they're only as reliable as what they're trained on and what they retrieve.
Research consistently shows that the majority of AI failures stem not from model limitations but from poor data. Biased datasets, incomplete records, conflicting sources, and stale information combine to create a perfect storm of unreliable outputs. In the era of predictive analytics, this meant bad dashboards and missed insights. In the era of generative and agentic AI, it means hallucinations, compliance violations, and automated mistakes at scale.
The new reality is simple: garbage in, hallucination out.
How Bad Data Breaks AI
The failure modes of bad data are well understood by engineers but less visible to business leaders. Here's how data quality issues translate into real business risk:
Bias and Distortion
Skewed datasets don't just produce inaccurate results. They amplify discrimination, generate poor recommendations, and create systematically unfair outcomes. In finance, biased training data can lead to discriminatory lending decisions. In HR, it can perpetuate hiring inequities. In personalization engines, it can lock users into filter bubbles that reduce engagement over time.
The problem isn't malicious intent. It's neglect. Historical data reflects historical bias, and AI systems trained on that data will reproduce it unless explicitly corrected.
Hallucinations and Inaccurate Outputs
When AI systems are fed incorrect or low-confidence data, they don't always flag uncertainty. Instead, they fabricate. They generate outputs that sound authoritative but are factually wrong. This becomes especially dangerous when users trust AI as a source of truth rather than a probabilistic tool.
A customer service agent powered by outdated product documentation will confidently provide wrong answers. A financial analysis tool working from incomplete transaction records will produce misleading forecasts. The outputs look professional. They're just wrong.
Fragmentation and Inconsistent Sources
Enterprise data lives in silos. CRM systems, ERP platforms, product logs, and third-party integrations all maintain their own versions of the truth. Customer records conflict. Sales figures don't match. Product availability data varies by system.
When autonomous agents act on this contradictory information, the results are unpredictable. One system says inventory is available; another says it's not. An agent places an order that can't be fulfilled. Fragmented data creates fragmented decisions.
Stale and Outdated Context
Real-time business requires real-time data. But many AI systems are making decisions based on last quarter's information, or worse, last year's. Market conditions shift. Customer preferences evolve. Competitive landscapes change.
AI making decisions on stale data is like driving while looking in the rearview mirror. You might stay on course if nothing changes. But the moment conditions shift, you're headed for a collision.
Lack of Metadata and Provenance
When AI systems can't validate where data came from, how recent it is, or how reliable it is, they can't make informed decisions about how to use it. Confidence scoring becomes impossible. Lineage tracking breaks down. Auditability disappears.
This isn't just a technical problem. It's a governance and compliance problem. Regulators increasingly expect organizations to explain how AI systems reached their conclusions. Without data provenance, that explanation is impossible.
Why This Is Becoming More Urgent
The shift from predictive to generative and agentic AI changes everything.
Predictive models generated insights. Business intelligence dashboards showed trends. Analytics tools surfaced patterns. When the data was wrong, the result was a bad report or a missed opportunity. Costly, but contained.
Generative and agentic AI systems don't just generate insights. They take action. They draft emails. They approve transactions. They schedule appointments. They make purchasing decisions. They interact with customers without human oversight.
The risk has moved from wrong answer to wrong action.
At the same time, regulatory pressure is mounting. GDPR, the NIST AI Risk Management Framework, ISO standards, and the EU AI Act all create new accountability requirements. Organizations must demonstrate that their AI systems are making decisions based on accurate, fair, and auditable data. Non-compliance carries financial and reputational consequences that far exceed the cost of fixing data quality issues.
The window for ignoring data quality is closing. The stakes are too high, and the visibility is too great.
The Fix: Building a High-Trust Data Foundation for AI
Fixing data quality isn't a one-time project. It's an ongoing discipline. Here's a practical framework for building and maintaining the data foundation that modern AI requires:
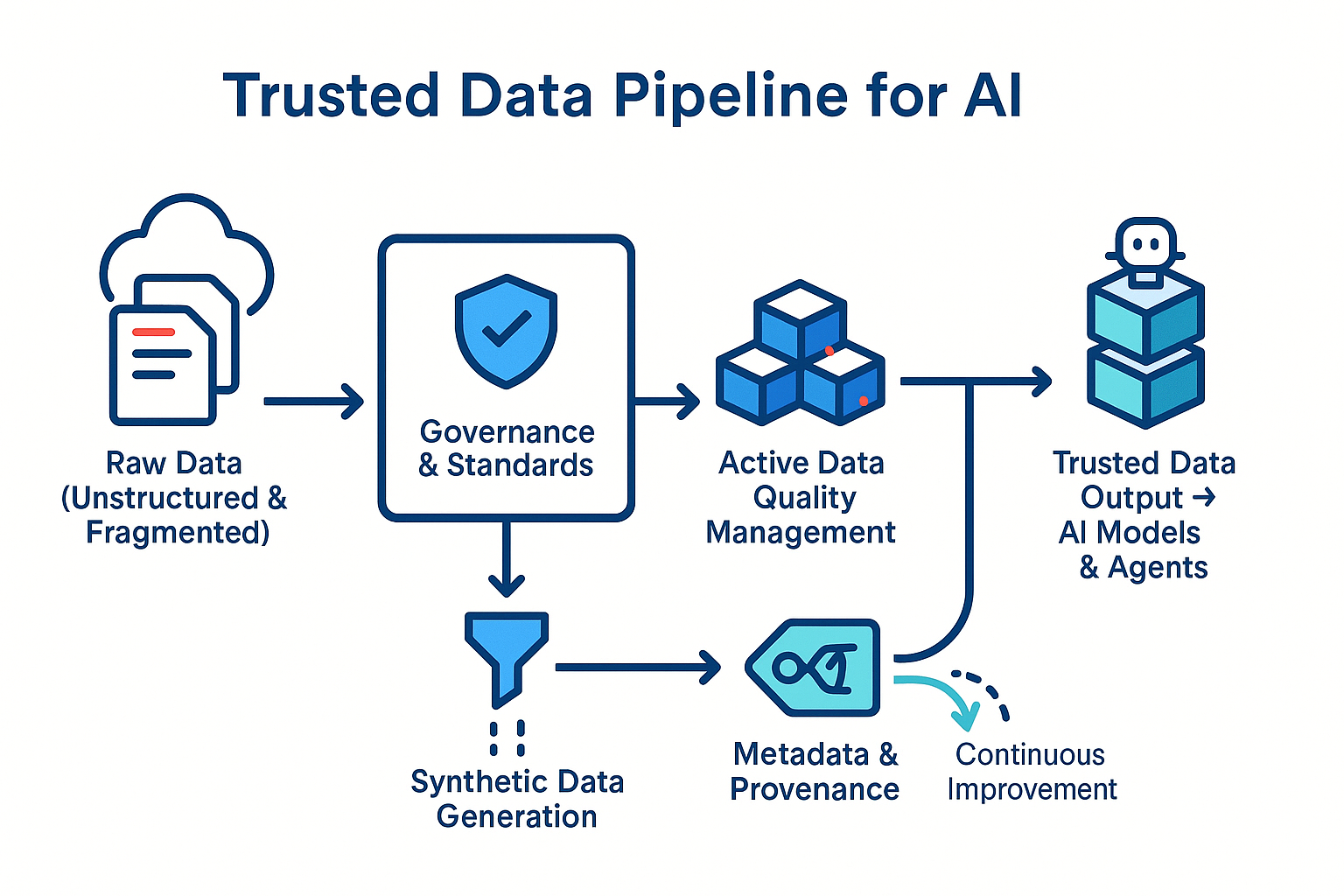
Data Governance 2.0
Traditional data governance focused on documentation. Policies lived in SharePoint. Data dictionaries were static spreadsheets. Access control was manual and reactive.
Modern data governance must be dynamic and automated. Policy enforcement should happen in real time. Access controls should adapt based on context, sensitivity, and user behavior. Oversight should be continuous, not periodic.
This shift requires tooling that can monitor data flows, detect anomalies, enforce policies automatically, and provide visibility across the entire data lifecycle. Governance becomes infrastructure, not documentation.
Active Data Quality Management
Waiting for users to report data issues is too slow. Organizations need continuous profiling, automated anomaly detection, and proactive correction pipelines.
Key metrics to track include accuracy (is the data correct?), completeness (are there gaps?), consistency (do sources agree?), timeliness (is it current?), and lineage (where did it come from?). These metrics should be monitored constantly, with alerts triggered when thresholds are breached.
The goal is to catch data quality issues before they propagate into AI outputs.
Synthetic and Real Data Blending
Synthetic data can fill gaps when real data is scarce, sensitive, or biased. It can help balance datasets, protect privacy, and accelerate testing. But it comes with risks.
The key is knowing when synthetic data helps and when it increases bias. Synthetic data generated from biased real data will inherit that bias. Synthetic data that doesn't reflect real-world distributions will train models that fail in production.
Use synthetic data strategically, with clear guardrails and validation against real-world outcomes.
Metadata and Data Provenance Automation
Every data point should carry metadata about its origin, its confidence level, and its intended use. Data lineage tracking should be automatic, not manual.
When agentic AI systems make decisions, they should be able to assess the trustworthiness of the data they're using. Low-confidence data should trigger additional validation. High-confidence data should enable faster action. This requires metadata infrastructure that scales with the data itself.
Feedback Loops
AI systems generate valuable signals about data quality. User interactions reveal when outputs are wrong. Agent feedback highlights when data is inconsistent. Model telemetry shows when inputs are out of distribution.
These signals should feed back into data quality processes. Errors become training data for improvement. Anomalies trigger investigation. The system learns and adapts over time.
This creates a virtuous cycle: better data leads to better AI, which provides better feedback, which improves data further.
The Role of Agentic AI in Solving the Data Problem
The same technology creating new data quality challenges can also help solve them.
Autonomous data-cleaning agents can identify and correct errors at scale. Pattern-matching algorithms can detect drift, outliers, and anomalies across disparate systems. Validation agents can cross-check records against multiple sources and flag inconsistencies for review.
Looking ahead, we're moving toward self-healing data ecosystems where AI continuously monitors, validates, and corrects data quality issues without human intervention. The data layer becomes intelligent, adaptive, and self-maintaining.
This isn't science fiction. Early implementations are already in production at leading organizations. The technology exists. What's missing is the organizational commitment to deploy it.
Where to Start: A Practical Roadmap
For organizations overwhelmed by the scope of data quality challenges, here's a pragmatic path forward:
Start small. Identify a single high-impact workflow where AI is already deployed or planned. Focus data quality efforts there first. Success in one domain builds momentum and proves value.
Establish a baseline. Before you can improve, you need to measure. Define data quality metrics for your chosen workflow. Implement confidence scoring. Understand your starting point.
Implement continuous monitoring. Set up automated profiling and anomaly detection. Create alerts for quality thresholds. Make data quality visible in real time.
Automate governance. Move policy enforcement from documentation to infrastructure. Implement access controls that adapt based on context. Create audit trails that require no manual effort.
Iterate and scale. As AI moves from isolated use cases to autonomous agents to a full digital workforce, expand data quality practices accordingly. Each new capability requires a corresponding investment in data infrastructure.
This approach balances ambition with pragmatism. Quick wins prove value. Incremental progress builds capability. The organization learns what works before scaling across the enterprise.
Outcome: AI That Can Be Trusted
The payoff for investing in data quality is substantial and measurable.
Cost and risk reduction. Fewer hallucinations mean fewer errors. Fewer errors mean less rework, fewer customer complaints, and lower exposure to compliance violations. The cost of fixing bad AI outputs far exceeds the cost of preventing them.
Improved decision accuracy. Better data leads to better predictions, better recommendations, and better actions. The ROI of AI increases when the outputs are reliable.
Faster automation and adoption. Teams trust AI systems that consistently produce good results. Trust accelerates adoption. Adoption drives value. Organizations move faster when they're not constantly second-guessing their AI systems.
AI as a strategic differentiator. In a world where every organization has access to the same models, competitive advantage comes from execution. The companies that build superior data foundations will extract more value from AI than their peers.
The New Competitive Advantage
The companies that win with AI will be the ones that treat data as a living asset rather than a static artifact. They'll invest in governance, quality, and provenance. They'll build feedback loops and self-healing systems. They'll recognize that in the era of autonomous AI, data quality isn't an IT task. It's a business imperative.
The model wars are a distraction. The real battle is over data. Organizations that understand this are building the foundation for durable competitive advantage. Those that don't will spend the next decade cleaning up the mess their AI systems create.
The choice is clear. The time to act is now.