
Beyond Retrieval: Why Agents Need Memory, Not Just Search
“The Simple Test: Ask your agent: “What did we try last time that didn’t work?” If it can’t answer, your RAG is broken.”
The "Goldfish" Problem
If you're building AI agents right now, you've probably noticed something frustrating. Your agent handles a complex task brilliantly, then five minutes later makes the exact same mistake it just recovered from. It's like working with someone who has no short-term memory.
This isn't a bug in your implementation. It's a design limitation. Most organizations are using Retrieval-Augmented Generation (RAG) to power their agents. RAG works great for what it was designed to do: answer questions by finding relevant documents. But agents don't just answer questions. They take action, encounter obstacles, adapt their approach, and learn from failure. That requires a different kind of intelligence.
The distinction matters more than you might think. RAG provides knowledge. Agents require wisdom. Knowledge is knowing what the documentation says. Wisdom is remembering that the last three times you followed that documentation, step four didn't work in your production environment.
To bridge this gap, we need to move from what I call "Stateless Search" to "Stateful Memory." The difference changes everything about how agents operate.
Why "Vanilla" RAG Fails Agents
Amnesia: The Stateless Trap
Standard RAG treats every query as if it's the first time your agent has ever encountered a problem. It has no object permanence. Each interaction starts from zero.
Here's what this looks like in practice: Your agent tries to call an API endpoint and gets a 404 error. It retrieves documentation about error handling, sees that the endpoint should exist, and tries again. Same error. It retrieves the same documentation again and tries a third time. Why? Because nothing in the RAG system stores the fact that this specific endpoint is currently broken.
The agent keeps searching for the answer in your knowledge base when the answer actually lives in its own recent experience. That experience gets discarded after each interaction because RAG wasn't built to remember what happened. It was built to find what's written down.
The "Shredded Book" Phenomenon
Vector databases chunk your documentation into small pieces to enable semantic search. This works well for finding paragraphs that match a query. It fails spectacularly when temporal sequence matters.
Imagine your company updates its data retention policy every year. Someone asks your agent about the current policy. The vector search retrieves the 2022 version because it has better keyword overlap with the query phrasing. The 2025 policy used different language, so it ranks lower. Your agent confidently cites outdated information because the search mechanism has no concept of recency or timeline.
The information exists. The retrieval system just doesn't understand that policies have versions, procedures have prerequisites, and events happen in order.
Experience vs. Fact
This gets to the core missing piece. RAG retrieves facts about what your documentation says. Agents need access to experience about what actually happened when they tried to apply those facts.
The manual says the approval workflow takes 24 hours. Your agent's experience shows it actually takes 72 hours because two of the required approvers are on the same continent and one is always asleep when the other submits. That experiential knowledge can't be retrieved from documentation. It has to be remembered from direct observation.
From Context to Memory
Let's clarify some terminology, because the industry uses these words inconsistently.
Context is like RAM in a computer. It's the information immediately available to your agent during a specific interaction. Context is expensive (every token costs money), volatile (it disappears when the conversation ends), and severely limited (even with extended context windows).
Memory is like a hard drive. It persists across sessions, grows over time, and can be structured to support different types of recall. More importantly, memory can evolve. What your agent believed yesterday can be updated based on what it learned today.
True agents need what cognitive scientists call a "dual-process architecture." They need to separate World Facts (external truth that doesn't change based on experience) from Beliefs (internal conclusions that do change based on experience).
Your documentation about API endpoints is a World Fact. Your agent's growing confidence that one of those endpoints is unreliable is a Belief that should strengthen each time the pattern repeats.
The "Hindsight" Architecture
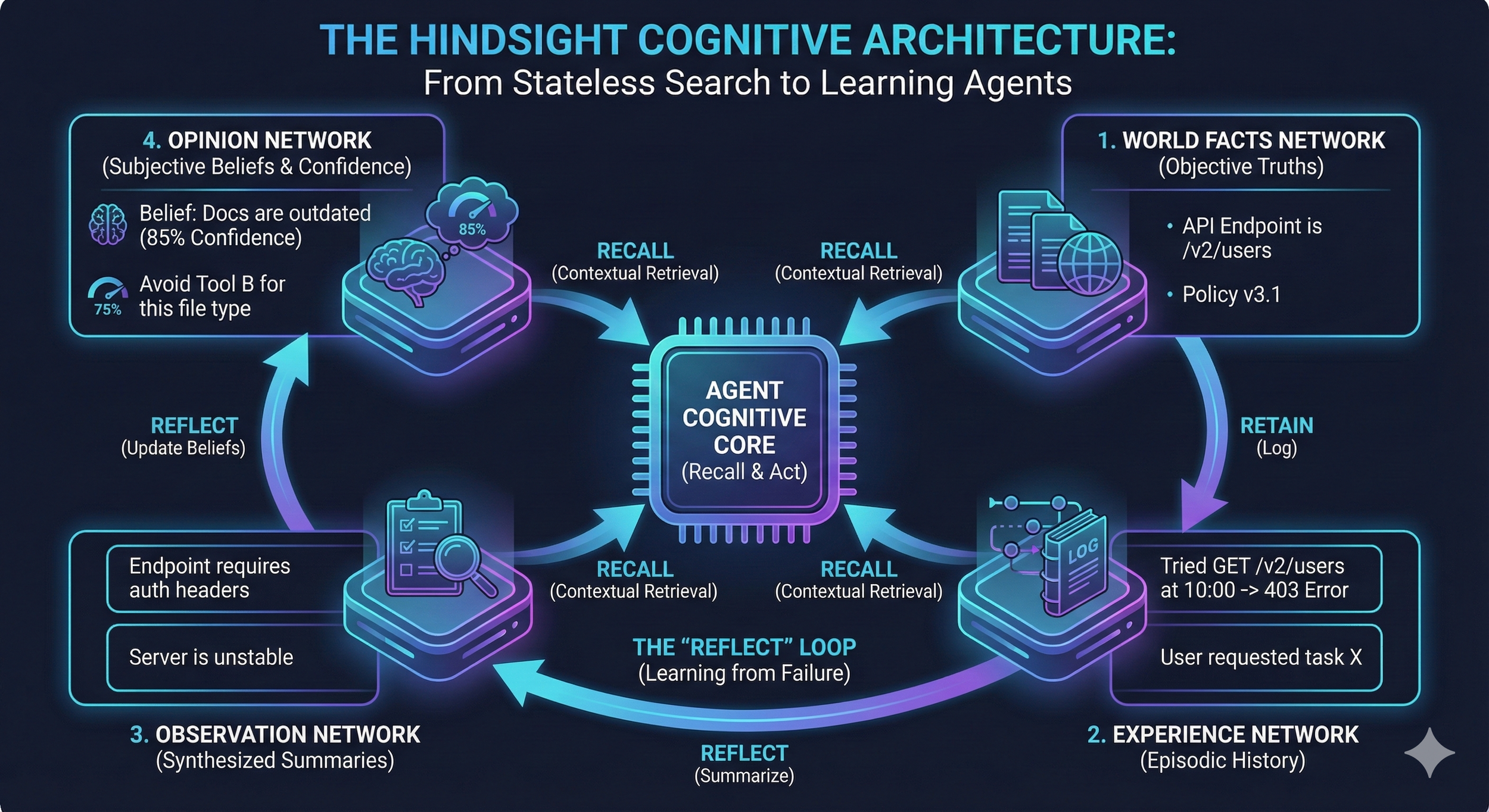
The breakthrough research here comes from a system called Hindsight, detailed in a paper titled "Hindsight is 20/20." It's the clearest example I've seen of what I call a "Memory-First" architecture.
Hindsight organizes agent memory into four separate networks, each serving a distinct cognitive function:
1. World Facts: This is your traditional knowledge base. Documentation, procedures, policy manuals. Immutable external truth that doesn't change based on what your agent experiences.
2. Experiences: This is your agent's diary. A chronological log of every action taken, every tool called, every result observed. "At 2:43 PM on Tuesday, I called the customer database API and received a timeout error."
3. Observations: These are summaries extracted from raw experiences. Instead of storing 500 individual API timeout errors, your agent stores "The customer database API times out frequently during business hours."
4. Opinions: These are confidence-weighted beliefs that evolve over time. "I believe the customer database API is unreliable (confidence: 0.87)." The confidence score adjusts based on continued experience.
The real innovation comes from what Hindsight calls the "Reflect" loop. After completing a task, the agent reviews its experience log and asks itself explicit questions: What went wrong? What worked better than expected? What assumptions did I make that turned out to be false?
This reflection updates the Opinion network. The agent literally "sleeps on it" and wakes up smarter. The next time a similar situation appears, the agent doesn't just retrieve documentation. It retrieves its own learned skepticism about whether that documentation will work.
This is how you build an agent that doesn't make the same mistake twice.
Created by Google Nano Banana Pro
What Else Is Available Today?
Hindsight isn't the only game in town. The broader landscape of memory systems is developing quickly.
GraphRAG (from Microsoft Research) takes a different approach. Instead of improving how agents remember their own experiences, GraphRAG improves how they understand relationships in your knowledge base.
Standard RAG finds documents through vector similarity. GraphRAG builds a knowledge graph that maps explicit relationships. It understands that Sarah reports to James, James reports to the CFO, and the CFO sets budget policy. When you ask about budget authority, GraphRAG can reason through the hierarchy instead of just finding documents that mention "budget."
This is particularly valuable for complex organizational questions where the answer requires connecting multiple pieces of information that might never appear in the same document.
MemGPT (now evolved into Letta) tackles the context window problem from a different angle. It treats memory management like an operating system, actively swapping information in and out of the agent's active context based on what's currently relevant.
Think of MemGPT as giving your agent the ability to take notes during a long meeting, refer back to those notes later, and summarize key points at the end. The full conversation might be too large to fit in context, but the agent can maintain coherent understanding across an extended interaction.
To frame the differences clearly:
- Hindsight is for learning from mistakes
- GraphRAG is for reasoning through complexity
- MemGPT is for maintaining continuity
Most production systems will eventually need some combination of all three.
The Path Forward
Here's my prediction: 2026 will be remembered as the year we moved from "RAG + Agents" to "Cognitive Architectures." The vector database will become one component of a larger memory system, not the entire foundation.
If you're building agents today, here's what you should do now:
Stop trying to stuff everything into the context window. You're optimizing for the wrong bottleneck. The limit isn't how much information you can cram into a single prompt. The limit is how well your agent can structure and recall the right information at the right time.
Start building an Episodic Log today. Even if you're not ready to implement a full memory system, begin logging every action your agent takes and every result it observes. Structure it as timestamped events. When you're ready to add real memory, you'll have training data from your own agent's actual experiences in your actual environment.
Separate facts from beliefs in your system design. Don't mix unchanging documentation with evolving observations. Build your architecture to treat them differently from day one. Your documentation retrieval and your experience retrieval need different query strategies and different update mechanisms.
The fundamental shift happening right now is this: We're moving from agents that search for answers to agents that remember what they learned. That's not a minor feature improvement. That's the difference between a search bar and a colleague.
If you want your agents to act like employees, stop treating them like search bars. Give them a memory.