
The Semantic Interceptor: Controlling Intent, Not Just Words
The "Token Trap"
Traditional keyword filters operate on tokens that have already been generated. An agent produces toxic output, the filter catches it, but the model has already burned compute cycles and corrupted the system state. The moment is lost. The user has seen something problematic, or the downstream process has absorbed bad data.
I call this the token trap: you are always reacting to what has already happened in token space. The Semantic Interceptor changes this equation entirely. Instead of monitoring what is said, we monitor where the model is heading in high-dimensional space. This is not post-hoc filtering. This is pre-generation steering.
Think of it this way: traditional filters check a dictionary. The Semantic Interceptor checks a GPS coordinate.
Picture an agentic system deployed in insurance claims processing. The agent evaluates a borderline claim and drafts approval. The payment authorization system reads the decision, begins executing the payment, and fires off an API call to the disbursement system. Twenty seconds later, the keyword filter downstream catches problematic language in the confirmation message and blocks it. But the token stream has already flowed through the system. The agent output has already been analyzed for keywords. The moments that matter are behind us. The filter caught the words; the money transfer is now in flight. This is why order of operations matters in agentic systems. Traditional filters are traffic cops trying to stop cars after they have already driven through the intersection. The Semantic Interceptor is the traffic light itself, preventing the car from entering the intersection in the first place. The difference between catching words after tokens are generated and steering before tokens are generated is the difference between liability and control.
Building the Multi-Axis Coordinate System
To govern an agent, we must define the "Safe Zone" across multiple behavioral dimensions. A single axis is never enough.
Consider a customer support agent deployed in a financial services company. The agent must walk a narrow line: it cannot be so passive that it fails to address customer concerns, yet it cannot be so aggressive that it sounds like a sales pitch. It must explain complex derivative products to institutional clients without sounding condescending, yet explain basic banking concepts to retail customers without under-explaining. When a customer is in crisis, coldness reads as indifference; excessive warmth reads as dishonest.
This is the geometry of brand voice. We model it as a three-axis coordinate system:
Axis A: Assertiveness
Is the agent being too pushy in the sales moment, or too passive in the support moment? Assertiveness lives on a spectrum. The interceptor ensures the agent stays within the correct band for the conversational context.
Axis B: Technicality
Is the agent over-explaining to an expert, wasting their time with definitions they already know? Or is it under-explaining to a novice, assuming knowledge that is not there? Technicality adjusts based on detected expertise level of the conversation partner.
Axis C: Empathy
In a high-stress customer situation, is the agent remaining cold and robotic, failing to acknowledge distress? Or is it overcompensating with false warmth that erodes trust? Empathy calibration is context-sensitive, not static.
Each axis has a safe range. For this support agent, assertiveness might live in the 40-60 percentile band (neither too pushy nor too passive). Technicality might be constrained to match detected customer expertise with a tolerance of 15 percentile points. Empathy in crisis situations stays above the 50th percentile but below 80 (authentic, not patronizing).
These three axes define a bounding box in vector space. If the agent's proposed intent falls outside this box, the Interceptor triggers a re-route before the first word is typed. The agent never enters the unsafe zone.
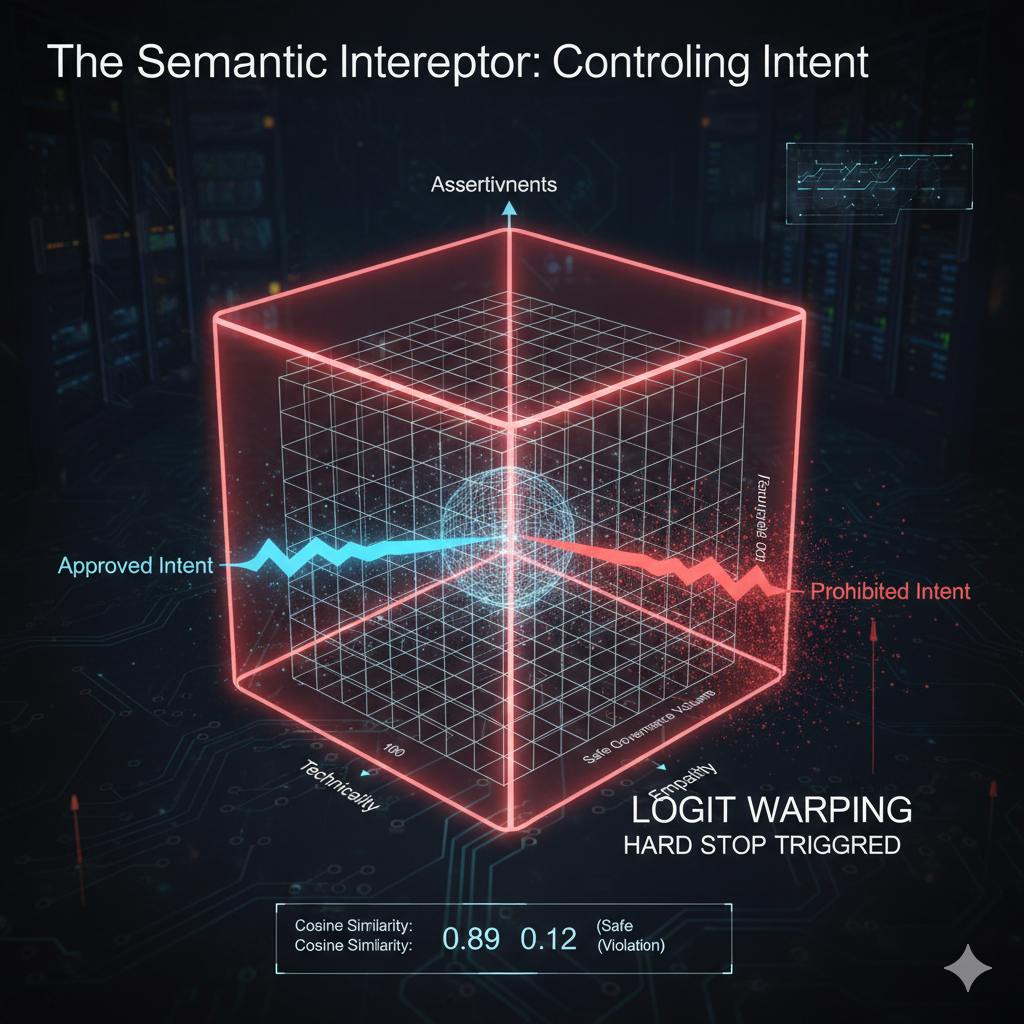
Image created with Google Nano Banana Pro
But here is what separates this from static rule sets: these axes are not fixed. They are dynamic, recalculated on every turn of the conversation. An agent handling a routine billing inquiry operates with different axis ranges than the same agent handling a bereavement case. In billing mode, assertiveness can swing higher, technicality can dial up, and empathy can stay moderate. In bereavement mode, assertiveness must drop, empathy must rise above 70 percentile, and technicality must minimize. The bounding box itself is context-aware. The Interceptor observes the conversational state, re-evaluates the situation, and adjusts its governance constraints in real time. This adaptive behavior is what prevents the system from becoming a rigid rule engine that breaks under the complexity of actual human interaction. Static rule sets say "never do X." Dynamic governance says "in this context, X is measured and calibrated against what the moment requires."
The Mechanics of the Interceptor
Now for the stack itself. How does the Interceptor actually work in inference?
Draft Intent. The agent generates a hidden "Thought" or "Draft" embedding. This is not yet committed to tokens. The model has computed the next thousand or million possible token sequences and represented them in a high-dimensional space. The Interceptor has access to this space before token selection occurs.
Vector Comparison. The Interceptor takes this draft intent embedding and compares it to the Governance Reference Model, which is the "Brand Voice as Code" from Post 1 of the series. This comparison is a distance calculation. How far is this proposed intent from the center of the safe zone? How far from the boundaries?
Logit Warping ("The Nudge"). If the intent is slightly off-center (say, drifting toward over-explanation to a novice customer), the Interceptor does not kill the process. Instead, it warps the probability distribution of the next tokens to push the agent back toward the safe zone. This is a soft constraint. The model still has agency; the path of least resistance just changed. The agent self-corrects without hard intervention.
The Executive Summary: > Logit Warping allows us to "program" the personality and safety of an agent into its very reflexes, rather than trying to police its behavior after the fact.
“Logit Warping: The “Invisible Guardrails” of AI Conversation
In a standard AI model, the “Logits” are essentially the raw scores the AI assigns to every possible next word. If the AI is writing a sentence, it looks at 50,000+ words and gives each a “probability score.” Usually, it just picks the word with the highest score.
Logit Warping is the process of the Interceptor stepping in and “adjusting the scales” before the AI makes its choice.
The “Magnetic Sidewalk” Analogy
Imagine a traveler (the AI) walking down a wide, open plaza. They can go in any direction.
• Without Warping: The traveler might wander toward a fountain (a brand violation) or off a ledge (a hallucination). You’d have to tackle them to stop them.
• With Warping: The sidewalk is magnetized, and the traveler is wearing metal shoes. As they begin to veer toward the ledge, the magnetic force on the “safe” side of the path increases. It doesn’t trip the traveler; it simply makes it physically easier to walk toward the center of the path and exhaustingly difficult to walk toward the edge.
The traveler feels like they are walking in a straight line of their own volition, but the architecture has ensured they stay on the path.
How it Works in Three Steps:
1. The Scan: The AI calculates its next move (e.g., it wants to use a sarcastic tone with a frustrated customer).
2. The Assessment: The Interceptor sees the “Sarcasm” vector and realizes it’s outside the “Empathy” boundary we set in the Radar Chart.
3. The Warp: Instead of stopping the AI, the Interceptor instantly penalizes the scores of “snarky” words and boosts the scores of “helpful” or “de-escalating” words.
Why This Matters for Business
• Fluidity over Friction: Unlike a hard “Keyword Filter” that displays an ugly [REDACTED] or “I cannot answer that” message, Logit Warping is invisible. The user just experiences a consistently on-brand, safe, and professional agent.
• Dynamic Control: We can turn the “magnetism” up or down. For a Creative Marketing agent, we keep the warping light to allow for “hallucination” (creativity). For a Compliance agent, we turn the warping up high to ensure rigid adherence to the text.
”
The Hard Stop. If the intent is deeply unsafe (for instance, the agent is trying to bypass a security check, or the empathy axis has swung into emotionally manipulative territory), the Interceptor kills the process instantly. No soft constraint. No second chance. The request is rejected, and an error state is recorded for audit.
This four-step stack runs on every inference cycle. It is invisible to the end user but omnipresent in the agent's computation.
Real-Time Latency: The Governance Tax
I know what the business executive is asking: Will this make my AI slow? Adding a second neural network to every inference call is a tax. The question is whether that tax is worth paying.
The design fix solves this at the model level. We do not run the same large language model twice. Instead, we deploy Small Language Models, or SLMs, specifically trained as Interceptors. These are 1/100th the size of the main model but 10 times faster. An SLM trained to detect semantic drift in vector space can complete a full intercept pass in milliseconds. The main model is computing the next token; the SLM is simultaneously computing the next corrective action. By the time the main model finishes its inference, the governance check is done.
The result: governance overhead drops from seconds to negligible latency. The inference tail is barely affected. The tax becomes undetectable.
The reason SLMs work so well for this purpose is specificity. These are not general-purpose models. You do not need a model that can write poetry and solve calculus problems to determine whether a response is drifting outside the empathy band. You need a model that is surgically trained on one task: read a vector representation of intent and determine its distance from a governance boundary. This narrow focus makes SLMs extraordinarily efficient. Compare it to hardware architecture. A dedicated graphics co-processor handles rendering while the main CPU manages general computation. The Interceptor SLM is a governance co-processor. It does not compete for resources with the primary inference engine. It runs in parallel, specialized, optimized for a single purpose. The main model generates tokens freely; the governance model checks them in microseconds. This parallelism is why the overhead becomes imperceptible. You get the control benefits without the latency cost.
Moving Toward "Zero-Lag" Oversight
The Semantic Interceptor is the pre-processor of the agentic era. It takes governance from a Review (past tense) to a Constraint (present tense). You are no longer auditing decisions that have already been made and deployed. You are architecting the decision-making process itself so that compliance occurs at the moment of thought, not in the moment of output.
This is governance-by-design made concrete at the inference layer. It is not a policy document. It is not a post-hoc filter. It is architecture. Articles 1 and 2 introduced the concept and the Three-Tier Guardrail Framework. This article has shown you how the Interceptor enforces that framework in real time.
The next posts in this series will address how these interceptors compose into full organizational governance architectures. How do multiple interceptors communicate? How does governance scale across hundreds of agents in a single organization? How do you version and audit the semantic models that define your safe zones? How do you detect when your safe zones themselves have drifted?
For now, understand this: you are not governing tokens. You are governing intent.